
対象読者
今回はGANに畳み込み層を追加して、よりリアルな偽物画像を生成していきます(DCGAN)。
DCGANモデルを使って、MNISTデータに似た画像(偽物)を生成して、前回よりも、より鮮明で、本物と見分けがつかないレベルまで学習することをやっていきましょう!
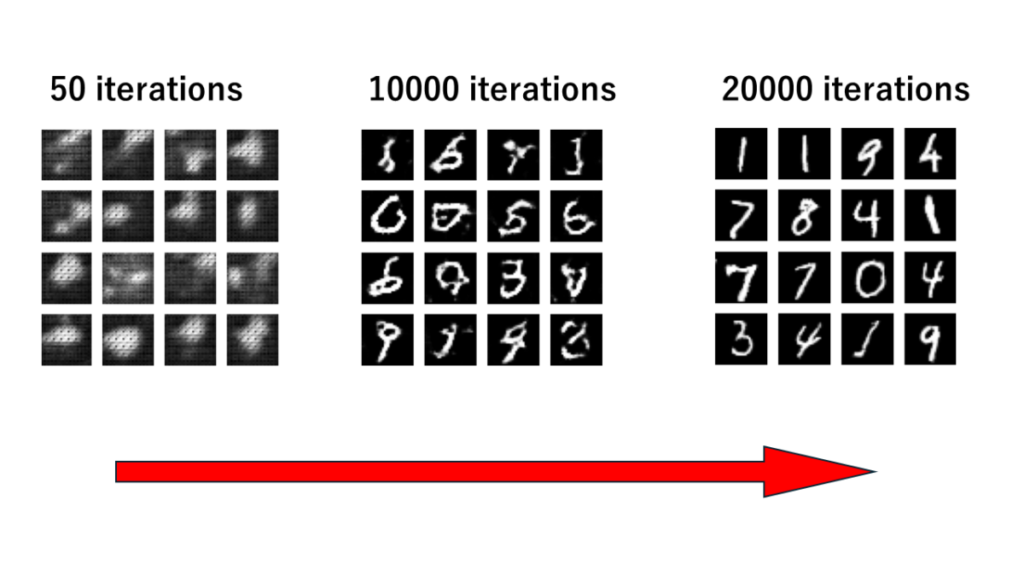
では、ただのGAN(前回)とDCGAN(今回)と本物のMNIST画像を比較してみましょう。

どうですか?もう、本物と見分けがつきませんよね。たまにニュースで聞くディープフェイクなんかもこの技術が使われたりします。そんなすごい技術を今日は簡単に構築していきます。
また、今日はほとんど前回とコーディングが被っているので楽にできますよ~。
そのため、細かい解説などは割愛させていただきます。

今回の全コード
import matplotlib.pyplot as plt
import numpy as np
from keras.datasets import mnist
import os
from keras.layers import Dense, Flatten, Reshape, LeakyReLU, Dropout
from keras.models import Sequential
from keras.optimizers import Adam
from keras.layers import Activation, BatchNormalization
from keras.layers import Conv2D, Conv2DTranspose
width = 28
height = 28
channels = 1
shape = (width, height, channels)
noise_dim = 100
def generator_model(noise_dim):
model = Sequential()
model.add(Dense(256 * 7 * 7, input_dim=noise_dim))
model.add(Reshape((7, 7, 256)))
model.add(Conv2DTranspose(128, kernel_size=3, strides=2, padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
model.add(Conv2DTranspose(64, kernel_size=3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
model.add(Conv2DTranspose(1, kernel_size=3, strides=2, padding='same'))
model.add(Activation('tanh'))
return model
def discriminator_model(shape):
model = Sequential()
model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=shape, padding='same'))
model.add(LeakyReLU(alpha=0.01))
model.add(Dropout(0.25))
model.add(Conv2D(64, kernel_size=3, strides=2, padding='same'))
model.add(LeakyReLU(alpha=0.01))
model.add(Conv2D(128, kernel_size=3, strides=2, padding='same'))
model.add(LeakyReLU(alpha=0.01))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
return model
def gan_model(generator, discriminator):
model = Sequential()
model.add(generator)
model.add(discriminator)
return model
discriminator = discriminator_model(shape)
discriminator.compile(loss='binary_crossentropy',
optimizer=Adam(lr=0.0001, beta_1=0.5),
metrics=['accuracy'])
generator = generator_model(noise_dim)
generator.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0003, beta_1=0.5))
discriminator.trainable = False
gan = gan_model(generator, discriminator)
gan.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0003, beta_1=0.5))
losses = []
accuracies = []
iteration_checkpoints = []
def train(iterations, batch_size, sample_interval):
(X_train, _), (_, _) = mnist.load_data()
X_train = X_train / 127.5 - 1.0
X_train = np.expand_dims(X_train, axis=3)
real_label = np.ones((batch_size, 1))
fake_label = np.zeros((batch_size, 1))
for iteration in range(iterations):
idx = np.random.randint(0, X_train.shape[0], batch_size)
batch_images = X_train[idx]
z = np.random.normal(0, 1, (batch_size, noise_dim))
gene_imgs = generator.predict(z)
d_loss_real = discriminator.train_on_batch(batch_images, real_label)
d_loss_fake = discriminator.train_on_batch(gene_imgs, fake_label)
d_loss, accuracy = 0.5 * np.add(d_loss_real, d_loss_fake)
z = np.random.normal(0, 1, (batch_size, noise_dim))
g_loss = gan.train_on_batch(z, real_label)
if (iteration + 1) % sample_interval == 0:
losses.append((d_loss, g_loss))
accuracies.append(100.0 * accuracy)
iteration_checkpoints.append(iteration + 1)
print("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (iteration + 1, d_loss, 100.0 * accuracy, g_loss))
save_images(generator, iteration + 1)
def save_images(generator, iteration, directory='dcgan_images', image_grid_rows=4, image_grid_columns=4):
if not os.path.exists(directory):
os.makedirs(directory)
z = np.random.normal(0, 1, (image_grid_rows * image_grid_columns, noise_dim))
gene_imgs = generator.predict(z)
gene_imgs = 0.5 * gene_imgs + 0.5
fig, axs = plt.subplots(image_grid_rows, image_grid_columns, figsize=(4, 4), sharey=True, sharex=True)
cnt = 0
for row in range(image_grid_rows):
for col in range(image_grid_columns):
axs[row, col].imshow(gene_imgs[cnt, :, :, 0], cmap='gray')
axs[row, col].axis('off')
cnt += 1
fig.savefig(f"{directory}/iteration_{iteration}.png")
plt.close(fig)
iterations = 20000
batch_size = 128
sample_interval = 50
train(iterations, batch_size, sample_interval)
generator.save('DC_generator.keras')
discriminator.save('DC_discriminator.keras')
gan.save('dcgan_model.keras')モジュールの準備
必要な素材をまずは準備しましょう!
import matplotlib.pyplot as plt
import numpy as np
from keras.datasets import mnist
from keras.layers import Dense, Flatten, Reshape,LeakyReLU
from keras.models import Sequential
from keras.optimizers import Adam
import os
#上記↑は前回と同じ
from keras.layers import Activation, Dropout,BatchNormalization
from keras.layers import Conv2D, Conv2DTransposefrom keras.layers import Activation, Dropout, BatchNormalization
#KerasのlayersモジュールからActivation、Dropout、BatchNormalizationクラスをインポートしています。
#Activationは活性化関数を定義するために使用されます。ニューラルネットワークの各層で活性化関数が適用され、モデルの非線形性を導入します。
#Dropoutは、過学習を防ぐためにランダムにノードを無効にすることによって、ネットワークの一部を無効にします。これにより、モデルが特定のパターンに過度に適合するのを防ぎます。
#BatchNormalizationは、トレーニングプロセス中に層の出力を標準化することによって、学習を安定化させ、収束を早めます。各バッチごとに平均と分散を計算することで、モデルが訓練データに過剰に適合する(過学習)リスクを軽減します。from keras.layers import Conv2D, Conv2DTranspose
#KerasのlayersモジュールからConv2DとConv2DTransposeクラスをインポートしています。
#Conv2Dは、2次元の畳み込み層を表します。畳み込み演算は、画像や音声などのデータで局所的なパターンを検出するのに使用されます。
#Conv2DTransposeは、転置畳み込みと呼ばれる操作を行います。これは、畳み込み演算の逆操作であり、入力の次元を増やすために使用されます。一般的には、画像のアップサンプリングやセグメンテーションなどのタスクで使用されます。

生成画像の型を定義
出力される画像の型を定義しておきましょう!
width=28
height=28
channels=1
shape=(width,height,channels)
noise_dim=100前回と同じのため解説は割愛します。
生成器(ジェネレーター)モデルを定義
ここで、畳み込み技術を用いてよりリアルな画像を生成できる仕組みを作っていきましょう!
def generator_model(noise_dim):
model = Sequential()
model.add(Dense(256 * 7 * 7, input_dim=noise_dim))
model.add(Reshape((7, 7, 256)))
model.add(Conv2DTranspose(128, kernel_size=3, strides=2, padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
model.add(Conv2DTranspose(64, kernel_size=3, strides=1, padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
model.add(Conv2DTranspose(1, kernel_size=3, strides=2, padding='same'))
model.add(Activation('tanh'))
return modeldef generator_model(noise_dim):
#generator_modelという関数を定義しています。この関数は、ノイズの次元数(noise_dim)を引数として受け取ります。model = Sequential()
#Sequentialモデルを作成します。Sequentialモデルは、層を積み重ねてシーケンシャルにネットワークを構築するためのKerasの一般的な方法です。model.add(Dense(256*7*7, input_dim=noise_dim))
#全結合層(Dense層)を追加します。入力次元はnoise_dimで指定されたノイズの次元数です。出力次元は256 * 7 * 7であり、これは後続の畳み込み層に適した形状です。model.add(Reshape((7, 7, 256)))
#Reshape層を追加して、出力を3次元テンソルに変形します。ここでは、出力を (7, 7, 256) の形状に変形しています。model.add(Conv2DTranspose(128, kernel_size=3, strides=2, padding='same'))
#転置畳み込み層(Conv2DTranspose層)を追加します。これにより、特徴マップのサイズが拡大されます。128個のフィルターを使用し、カーネルサイズは3×3です。また、ストライドは2で、パディングは’same’です。
model.add(BatchNormalization())
#BatchNormalization層を追加して、ネットワークの安定化と学習の収束を改善します。
model.add(LeakyReLU(alpha=0.01))
#LeakyReLU活性化関数を追加します。これは、通常のReLU関数に比べて負の領域でわずかに傾いた特性を持ち、勾配消失問題を緩和します。
model.add(Conv2DTranspose(64, kernel_size=3, strides=1, padding=’same’))
#64
: 出力フィルター数。つまり、このレイヤーが出力する特徴マップの数です。
#kernel_size=3
: カーネル(フィルター)のサイズ。この場合、3×3のカーネルが使用されます。
strides=1
: ストライドのサイズ。畳み込み操作を適用する際の移動量を指定します。この場合、ストライドは1となります。
padding=’same’
: パディングの種類を指定します。’same’を指定することで、入力と同じサイズの出力が得られるように入力にパディングが追加されます。
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.01))
#上記で解説済みmodel.add(Conv2DTranspose(1, kernel_size=3, strides=2, padding='same'))
#最後の転置畳み込み層では、1つのチャンネルの画像が生成されます(kernel_size、strides、paddingによってサイズが調整されます)。
model.add(Activation('tanh'))
#tanh活性化関数が適用されます。これにより、出力が[-1, 1]の範囲にスケーリングされます。これは、一般的に画像のピクセル値がこの範囲に収まるようにするためです。return model
#完成した生成器モデルを返します。
識別器(ディスクリミネーター)モデルを定義
識別器も作っていきましょう。また、識別器は生成器よりも強くなりやすいので、Dropoutを追加したり、正規化は行わず性能を上げ過ぎないようにします。
def discriminator_model(shape):
model = Sequential()
model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=shape, padding='same'))
model.add(LeakyReLU(alpha=0.01))
model.add(Dropout(0.25))
model.add(Conv2D(64, kernel_size=3, strides=2, padding='same'))
model.add(LeakyReLU(alpha=0.01))
model.add(Conv2D(128, kernel_size=3, strides=2, padding='same'))
model.add(LeakyReLU(alpha=0.01))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
return modeldef discriminator_model(shape):
#discriminator_modelという関数を定義しています。この関数は、入力画像の形状(shape)を引数として受け取ります。
model = Sequential()
#Sequentialモデルを作成します。
model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=shape, padding='same'))
#畳み込み層(Conv2D層)を追加します。32個のフィルターを使用し、カーネルサイズは3×3です。ストライドは2で、パディングは’same’です。input_shapeは、入力画像の形状を指定します。model.add(LeakyReLU(alpha=0.01))
#LeakyReLU活性化関数を追加します。これは、通常のReLU関数に比べて負の領域でわずかに傾いた特性を持ち、勾配消失問題を緩和します。
model.add(Dropout(0.25))
# Dropoutを追加することで、過学習を抑制できる。
model.add(Conv2D(64, kernel_size=3, strides=2, padding=’same’))
#上記で解説済み
model.add(LeakyReLU(alpha=0.01))
#上記で解説済み
model.add(Conv2D(128, kernel_size=3, strides=2, padding=’same’))
#上記で解説済み
model.add(LeakyReLU(alpha=0.01))
#上記で解説済み
model.add(Flatten())
#Flatten層を追加して、畳み込み層からの出力をフラットなベクトルに変換します。これにより、全結合層に接続することができます。model.add(Dense(1, activation='sigmoid'))
#全結合層(Dense層)を追加します。1つのノードがあり、出力の活性化関数としてシグモイド関数が使用されています。これにより、識別器は入力画像が本物である確率を出力します(0から1の間の値)。
DCGANモデルの定義とコンパイル
生成器と識別器を結合してDCGANモデルを作成しましょう!
def gan_model(generator,discriminator):
model=Sequential()
model.add(generator)
model.add(discriminator)
return modelこれは、前回と全く一緒です。
モデルのコンパイル
GANモデルはパラメーターに敏感に反応するので、慎重にパラメーターを設定していきましょう!
discriminator = discriminator_model(shape)#前回と同じ
discriminator.compile(loss='binary_crossentropy',
optimizer=Adam(lr=0.0001, beta_1=0.5),
metrics=['accuracy'])#追加コード
generator = generator_model(noise_dim)#前回と同じ
generator.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0003, beta_1=0.5))#追加コード
discriminator.trainable = False#前回と同じ
gan = gan_model(generator, discriminator)#前回と同じ
gan.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0003, beta_1=0.5))#追加コードこちらも、大枠では前回とほぼ同じです。しかし、今回は細かな設定を変えたり、追加したりしています。前回と同じコードは基本、解説は割愛します。
discriminator = discriminator_model(shape)
#前回と同じ
discriminator.compile(loss=’binary_crossentropy’,optimizer=Adam(lr=0.0001, beta_1=0.5),metrics=[‘accuracy’])
#Adam()の学習率を0.0001にしている。ちなみにデフォルト値は0.001です。
#beta_1はDCGANでは0.5が一般的な選択肢
#それ以外は前回と共通
generator = generator_model(noise_dim)
#前回と同じ
generator.compile(loss=’binary_crossentropy’, optimizer=Adam(lr=0.0003, beta_1=0.5))
#Adam()での生成器の学習率は識別器よりも大きくするのが一般的。生成器の方が最初は不利なので、その分プラスさせている。
discriminator.trainable = False
#前回と同じ
#trainable属性を使用して、特定のモデルまたはレイヤーのトレーニング可能なパラメータを無効にする操作です。識別器のすべてのトレーニング可能なパラメータ(重み)を「フリーズ」することを意味します。つまり、この行以降で行われる識別器へのバックプロパゲーションによる更新は、識別器の重みには反映されません。この操作により、生成器のみが更新され、識別器の重みは固定された状態でトレーニングが行われます。
gan = gan_model(generator, discriminator)
#前回と同じ
gan.compile(loss=’binary_crossentropy’, optimizer=Adam(lr=0.0003, beta_1=0.5))
#Adam()での生成器の学習率は識別器よりも大きくするのが一般的。識別器の方が強すぎると、ほとんどが偽とはじかれてどれを修正したらいいか分からなくなる。→学習が進まなくなる
モデルの訓練
ここも、前回と全く同じでも動作します。しかし、今回は少しだけ遊び心で変えてみました。
losses = []
accuracies = []
iteration_checkpoints = []
def train(iterations, batch_size, sample_interval):
(X_train, _), (_, _) = mnist.load_data()
X_train = X_train / 127.5 - 1.0
X_train = np.expand_dims(X_train, axis=3)
real_label = np.ones((batch_size, 1))
fake_label = np.zeros((batch_size, 1))
for iteration in range(iterations):
idx = np.random.randint(0, X_train.shape[0], batch_size)
batch_images = X_train[idx]
z = np.random.normal(0, 1, (batch_size, noise_dim))
gene_imgs = generator.predict(z)
d_loss_real = discriminator.train_on_batch(batch_images, real_label)
d_loss_fake = discriminator.train_on_batch(gene_imgs, fake_label)
d_loss, accuracy = 0.5 * np.add(d_loss_real, d_loss_fake)
z = np.random.normal(0, 1, (batch_size, noise_dim))#前回と違って今回はこれを追加する
#前回はここにdiscriminator.trainable = Falseを入れたが今回は削除
g_loss = gan.train_on_batch(z, real_label)
#前回はここにdiscriminator.trainable = True を入れたが今回は削除
if (iteration + 1) % sample_interval == 0:
losses.append((d_loss, g_loss))
accuracies.append(100.0 * accuracy)
iteration_checkpoints.append(iteration + 1)
print("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (iteration + 1, d_loss, 100.0 * accuracy, g_loss))
save_images(generator, iteration + 1)discriminator.trainable = Falseとdiscriminator.trainable = Trueはあってもなくても結果が変わらないことに気づいたので、今回は削除して訓練をすることにした。
z = np.random.normal(0, 1, (batch_size, noise_dim))
#このコードは2回使われている(15行と22行)。1回目は偽の画像を生成するためにつかわれ、2回目はGeneratorを訓練するために使われます。
#同じノイズを使い回すと、Generatorが学習するデータの多様性が制限されます。つまり、同じノイズから生成された画像は似通ってしまい、多様な画像を生成する能力が制限される可能性があります。→モード崩壊につながる
要するに、今回やったことはdiscriminator.trainable = Falseとdiscriminator.trainable = Trueを削除した代わりに、z = np.random.normal(0, 1, (batch_size, noise_dim))で補ったということです。
紛らわしくしてすみません!でも、どうしても試してみたくなってしまいました。
生成画像の保存
画像を保存して目視できるようにしましょう!
def save_images(generator, iteration, directory='dcgan_directory', image_grid_rows=4, image_grid_columns=4):
if not os.path.exists(directory):
os.makedirs(directory)
z = np.random.normal(0, 1, (image_grid_rows * image_grid_columns, noise_dim))
gene_imgs = generator.predict(z)
gene_imgs = 0.5 * gene_imgs + 0.5
fig, axs = plt.subplots(image_grid_rows, image_grid_columns, figsize=(4, 4), sharey=True, sharex=True)
cnt = 0
for row in range(image_grid_rows):
for col in range(image_grid_columns):
axs[row, col].imshow(gene_imgs[cnt, :, :, 0], cmap='gray')
axs[row, col].axis('off')
cnt += 1
fig.savefig(f"{directory}/iteration_{iteration}.png")
plt.close(fig)保存されるデフォルトディレクトリの名前をdcganにしました。それ以外は前回と同じです。
モデルの実行
バッチサイズを変えると、学習に影響が出ます。それ以外のパラメーターはお好みでどうぞ!
iterations=20000
batch_size=128
sample_interval=1000
train(iterations,batch_size,sample_interval)sample_interval=1000
#画像や評価が出力される間隔です。
#この数を変化させても、学習には影響はありません。適度にみたいのなら、500などの小さい数字にしてもいいかもです。
モデルの保存とロード方法
今回学習したモデルを再利用するために、保存しておきましょう!
#モデルの保存
generator.save('DCGAN_generator.keras')
discriminator.save('DCGAN_discriminator.keras')
gan.save('DCGAN_model.keras')#モデルのロード方法
from keras.models import load_model
# 保存されたモデルをロード
loaded_model = load_model('DCGAN_generator.keras')上書きを防ぐために前回とファイル名を変えました。
それ以外はすべて同じ流れです。
ファイルの実行
では、実行していきましょう。実行方法は人それぞれですが、私の場合はCMDでファイル名を入力することで実行しています。
ファイル名.pyこれで、いい感じの出力がされたら完了です!
p.s. 1000イテレーションで8分です。つまり20000イテレーションは160分くらいかかります。(=2.6時間)
出力例
50 [D loss: 0.000624, acc.: 100.00%] [G loss: 0.007994]
100 [D loss: 0.694652, acc.: 54.69%] [G loss: 1.168186]
150 [D loss: 0.732862, acc.: 40.23%] [G loss: 0.726937]
200 [D loss: 0.756426, acc.: 33.20%] [G loss: 0.835835]
300 [D loss: 0.711406, acc.: 36.33%] [G loss: 0.747646]
350 [D loss: 0.703592, acc.: 44.53%] [G loss: 0.748230]
400 [D loss: 0.679182, acc.: 60.55%] [G loss: 0.719221]
500 [D loss: 0.684259, acc.: 54.30%] [G loss: 0.721480]
600 [D loss: 0.685240, acc.: 57.42%] [G loss: 0.719235]
700 [D loss: 0.695925, acc.: 49.61%] [G loss: 0.702438]
800 [D loss: 0.696105, acc.: 50.00%] [G loss: 0.697281]
900 [D loss: 0.688253, acc.: 56.25%] [G loss: 0.704283]
1000 [D loss: 0.687551, acc.: 56.25%] [G loss: 0.706025]
1350 [D loss: 0.697760, acc.: 48.44%] [G loss: 0.717108]
1400 [D loss: 0.686100, acc.: 53.91%] [G loss: 0.708159]
2000 [D loss: 0.659652, acc.: 60.16%] [G loss: 0.790444]
3000 [D loss: 0.645585, acc.: 62.50%] [G loss: 0.880491]
4000 [D loss: 0.553337, acc.: 74.22%] [G loss: 1.089478]
~
14000 [D loss: 0.467627, acc.: 78.12%] [G loss: 1.328423]
15000 [D loss: 0.543287, acc.: 69.92%] [G loss: 1.445801]
19000 [D loss: 0.486697, acc.: 75.00%] [G loss: 1.706172]
20000 [D loss: 0.515853, acc.: 72.27%] [G loss: 1.522569]![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/3a19e183.08365096.3a19e184.6a2b305f/?me_id=1278256&item_id=21826167&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Frakutenkobo-ebooks%2Fcabinet%2F0427%2F2000012260427.jpg%3F_ex%3D128x128&s=128x128&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")
おわりに
お疲れさまでした。時間があったら、自分でパラメータをいじってみて動向の変化を確かめてみるのも勉強になったりします。
次回は、カラー画像の生成をGANでやっていきます。
p.s.CPU性能の限界があるので、大した画像は生成できません🙇

