対象読者
今回は、DCGANでカラー画像を生成していきます!あまり良い結果とは言えませんが、カラー画像自体は生成できているので、まぁよしとしてください💦
今回のゴール設定は『タイプを具現化する』ことです。綺麗だと思う女性の画像を集め、それらに共通する特徴をDCGANで生成してもらいます。これにより、自分のタイプという概念が具現化できます。
ちなみに下が結果です。
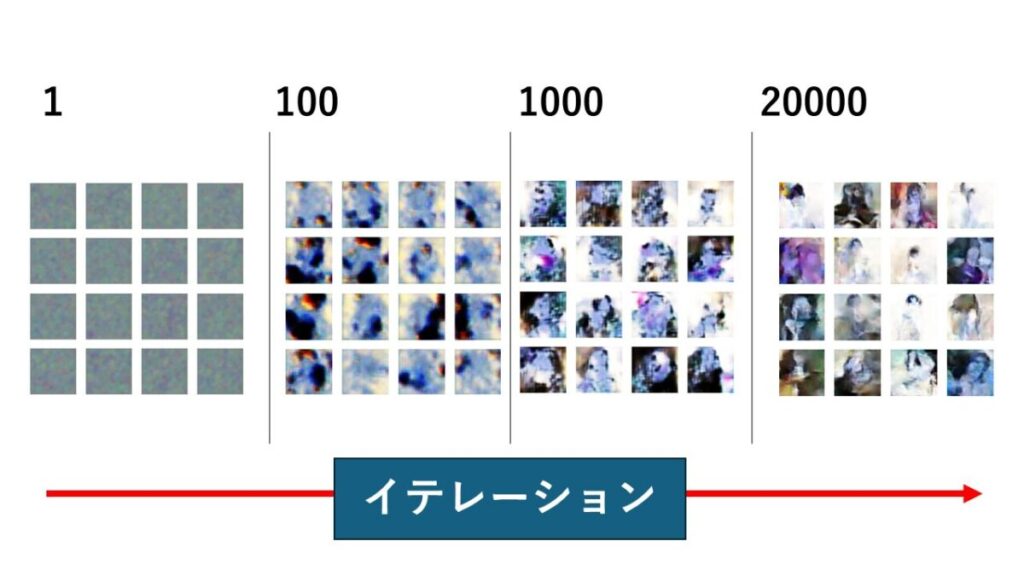
女性と思えば女性に見えるレベルの画像ですね(笑)
こんなレベルでもいいよ!と感じたら、読み進めてみてください。
今回のプロセス
では、まずはじめにDCGANでカラー画像生成プロセスを簡単に紹介しておきます。
- 画像収集
- 画像加工
- プログラミング(モデル作成)
1.モジュール準備
2.生成画像の型
3.生成器・識別器・GANモデルの構築
4.コンパイル
5.訓練
6.追加の関数とか
7.実行 - モデルの評価・改善
- 終了
簡単にまとめるとこんな感じです。コードは前回までのを使ったりするので、意外とすんなり終わります。
今回の全コード
半分以上はこれまでの『衝撃簡単シリーズ』で登場したものとなるので、新しいことは意外とありません。
p.s.前回まででの重複箇所の説明は割愛させていただきます
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers import LeakyReLU
from keras.layers import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam
import matplotlib.pyplot as plt
import os
import cv2
import numpy as np
width = 40
height = 40
channels = 3
shape = (width, height, channels)
noise_dim = 100
def generator_model(noise_dim):
model = Sequential()
model.add(Dense(10 * 10 * 256, activation="relu", input_dim=noise_dim))
model.add(Reshape((10, 10, 256)))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(3, kernel_size=3, padding="same"))
model.add(Activation("tanh"))
return model
def discriminator_model(shape):
model = Sequential()
model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
return model
def gan_model(generator, discriminator):
model = Sequential()
model.add(generator)
model.add(discriminator)
return model
discriminator = discriminator_model(shape)
discriminator.compile(loss='binary_crossentropy',
optimizer=Adam(lr=0.0001, beta_1=0.5),
metrics=['accuracy'])
generator = generator_model(noise_dim)
generator.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0003, beta_1=0.5))
discriminator.trainable = False
gan = gan_model(generator, discriminator)
gan.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0003, beta_1=0.5))
losses = []
accuracies = []
iteration_checkpoints = []
def train(iterations, batch_size, sample_interval):
X_train = load_images("./resized_images_40")
X_train = X_train / 127.5 - 1.0
real_label = np.ones((batch_size, 1)) # 修正
fake_label = np.zeros((batch_size, 1)) # 修正
for iteration in range(iterations):
idx_real = np.random.randint(0, X_train.shape[0] - 1, batch_size) # 修正
idx_fake = np.random.randint(0, X_train.shape[0] - 1, batch_size) # 修正
batch_images_real = X_train[idx_real]
batch_images_fake = X_train[idx_fake]
# ノイズの生成時に正しい次元数を使用する
z = np.random.normal(0, 1, (batch_size, noise_dim)) # 修正
gene_imgs = generator.predict(z)
d_loss_real = discriminator.train_on_batch(batch_images_real, real_label) # 修正
d_loss_fake = discriminator.train_on_batch(gene_imgs, fake_label)
d_loss, accuracy = 0.5 * np.add(d_loss_real, d_loss_fake)
z = np.random.normal(0, 1, (batch_size, noise_dim))
g_loss = gan.train_on_batch(z, real_label)
if (iteration + 1) % sample_interval == 0:
losses.append((d_loss, g_loss))
accuracies.append(100.0 * accuracy)
iteration_checkpoints.append(iteration + 1)
print("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (iteration + 1, d_loss, 100.0 * accuracy, g_loss))
save_images(generator, iteration + 1)
def save_images(generator, iteration, directory='face-gan_images', image_grid_rows=4, image_grid_columns=4):
if not os.path.exists(directory):
os.makedirs(directory)
z = np.random.normal(0, 1, (image_grid_rows * image_grid_columns, noise_dim))
gene_imgs = generator.predict(z)
gene_imgs = 0.5 * gene_imgs + 0.5
fig, axs = plt.subplots(image_grid_rows, image_grid_columns, figsize=(4, 4), sharey=True, sharex=True)
cnt = 0
for row in range(image_grid_rows):
for col in range(image_grid_columns):
axs[row, col].imshow(gene_imgs[cnt])
axs[row, col].axis('off')
cnt += 1
fig.savefig(f"{directory}/iteration_{iteration}.png")
plt.close(fig)
def load_images(directory):
images = []
for filename in os.listdir(directory):
img = cv2.imread(os.path.join(directory, filename))
if img is not None: # 画像の読み込みが成功した場合のみ処理を続行
img = cv2.resize(img, (width, height))
images.append(img)
else:
print(f"Warning: Failed to load image {filename}")
if len(images) == 0:
print("Error: No images loaded")
return None
else:
return np.array(images)
iterations = 20000
batch_size = 128
sample_interval = 1
train(iterations, batch_size, sample_interval)
generator.save('40x40color-Face-gene.keras')
discriminator.save('40x40color-Face-dis.keras')
gan.save('40x40color-Face-gan.keras')
カラー画像の収集+前処理
では、早速やっていきましょう。まずは画像収集と前処理です。具体的なコードはこちらでやってみてください。↓

ここのタスクで私がやったことをまとめます。
- 独断と偏見から綺麗だと思う女性画像を100枚ずつ計400枚集める
(有村架純・長澤まさみ・橋本環奈・パクジヒョ) - 画像サイズを40×40に変更する
- ファイル名を変更する
この3ステップをここではやりました。また、先ほど提供した記事でこれらすべてのプログラムコードをのせているので、誰でも簡単にできますよ。
モジュール準備
import matplotlib.pyplot as plt
import numpy as np
from keras.layers import Dense, Flatten,Reshape, LeakyReLU
from keras.models import Sequential
from keras.optimizers import Adam
import os
from keras.layers import Activation,Dropout,BatchNormalization
#上記↑は『衝撃簡単5』と同じ
from keras.layers import Conv2D
from keras.layers import UpSampling2D
import cv2
from keras.layers import Conv2D
#Conv2Dは入力データ(通常は画像や特徴マップ)に対して畳み込み演算を適用し、新しい特徴マップを生成するライブラリ
from keras.layers import UpSampling2D
#Upsampling2Dはアップサンプリングプロセスを行うためのライブラリ。
#Conv2DTransposeを使いたいが、計算量が大きくなってしまうのでやめました。
import cv2
#cv2は画像処理に使われるライブラリ
生成画像の型を定義
生成する画像の型を定義します。幅と高さを自分の生成したい大きさに調整します。また、チャンネルはカラーなので3にします。
width = 40
height = 40
channels = 3
shape = (width, height, channels)
noise_dim = 100生成器(ジェネレーター)モデルを定義
def generator_model(noise_dim):
model = Sequential()
model.add(Dense(10 * 10 * 256, activation="relu", input_dim=noise_dim))
model.add(Reshape((10, 10, 256)))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(3, kernel_size=3, padding="same"))
model.add(Activation("tanh"))
return modelmodel.add(Dense(10 * 10 * 256, activation=”relu”, input_dim=noise_dim))
#10 * 10 * 256は、出力の次元数を指定しており、10 * 10 * 256個のニューロンを持つ層を定義している。
#10は、アップサンプリングの数から導く。もし、アップサンプリング数が1つなら20を設定する。。model.add(Reshape((10, 10, 256)))
#直前の全結合層からの出力を(10, 10, 256)の形状に変更している。→テンソルを3次元の画像形式に変換できるmodel.add(BatchNormalization(momentum=0.8))
#:学習を安定化し、収束を加速するための手法を用いる
#momentum=0.8は、モーメンタムの値を指定する。更新において、ほぼ前回の更新の80%を保持して次のステップに反映させる。
#モーメンタム:収束速度を向上させ、局所的最適解からの脱出を助ける効果。一般的な値は0.9。
model.add(UpSampling2D())
# アップサンプリングは、画像のサイズを拡大する操作であり、ここでは画像を拡大している。デフォルトでは2倍に拡大される。→Dense層の入力はアップサンプリングを考慮する必要がある。model.add(Conv2D(128, kernel_size=3, padding="same"))
#Conv2Dは、2次元の畳み込みを行う層。画像データの処理において、畳み込み層はフィルター(カーネル)を用いて画像の特徴を抽出する
#引数は、畳み込み演算に使用するフィルターの数を指定している。ここでは128個のフィルターを使用している→128個は、モデルが十分な表現力を持ちつつも、計算コストを抑えつつ、多様な特徴を捉えるためのバランスの取れた選択肢
#kernel_size=3は、畳み込み演算に使用するフィルターのサイズを指定しています。ここでは3×3のフィルター
#padding="same"は、入力と出力のサイズを同じに保つために、入力画像の周囲にパディングを追加することを指定してる
*以降は、繰り返しなので割愛
model.add(Activation(“tanh”))
#tanh関数は、入力が無限に広がる範囲の実数を、 -1 から 1 の範囲にマッピングする関数→生成された画像のピクセル値を調整し、モデルが学習しやすくするために役立つ
#tanh関数は0 を中心とした対称的な出力を持つ→勾配の効率的な伝播を可能にする
識別器(ディスクリミネーター)を定義
def discriminator_model(shape):
model = Sequential()
model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
return model#生成器と逆に、カーネルサイズの増加は、特徴の抽象化の階層を作成する一つの方法。
①最初の層は画像の低レベルの特徴を取得し、
②その後の層はより抽象的な特徴を取得します。
このような階層的な抽象化は、識別器が画像の本質的な特徴を理解するのに役立つ
*このdiscriminatorコードは今までに何回も使っているので説明は割愛します。

DCGANモデルの定義とコンパイル
生成器と識別器を結合してDCGANモデルを作成しましょう!
def gan_model(generator, discriminator):
model = Sequential()
model.add(generator)
model.add(discriminator)
return modelこれも今までに何回も登場しました。もはや定型文ですね。
モデルのコンパイル
パラメーターの設定をしていきましょう。
discriminator = discriminator_model(shape)
discriminator.compile(loss='binary_crossentropy',
optimizer=Adam(lr=0.0001, beta_1=0.5),
metrics=['accuracy'])
generator = generator_model(noise_dim)
generator.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0003, beta_1=0.5))
discriminator.trainable = False
gan = gan_model(generator, discriminator)
gan.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0003, beta_1=0.5))こちらは、前回と一緒です。最初に見せたゴール画像よりも良質な画像を生成したい場合はカスタマイズして最適解を導いてみてください。
モデルの訓練
losses = []
accuracies = []
iteration_checkpoints = []
def train(iterations, batch_size, sample_interval):
X_train = load_images("./resized_images_40")
X_train = X_train / 127.5 - 1.0
real_label = np.ones((batch_size, 1)) # 修正
fake_label = np.zeros((batch_size, 1)) # 修正
for iteration in range(iterations):
idx_real = np.random.randint(0, X_train.shape[0] - 1, batch_size) # 修正
idx_fake = np.random.randint(0, X_train.shape[0] - 1, batch_size) # 修正
batch_images_real = X_train[idx_real]
batch_images_fake = X_train[idx_fake]
# ノイズの生成時に正しい次元数を使用する
z = np.random.normal(0, 1, (batch_size, noise_dim)) # 修正
gene_imgs = generator.predict(z)
d_loss_real = discriminator.train_on_batch(batch_images_real, real_label) # 修正
d_loss_fake = discriminator.train_on_batch(gene_imgs, fake_label)
d_loss, accuracy = 0.5 * np.add(d_loss_real, d_loss_fake)
z = np.random.normal(0, 1, (batch_size, noise_dim))
g_loss = gan.train_on_batch(z, real_label)
if (iteration + 1) % sample_interval == 0:
losses.append((d_loss, g_loss))
accuracies.append(100.0 * accuracy)
iteration_checkpoints.append(iteration + 1)
print("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (iteration + 1, d_loss, 100.0 * accuracy, g_loss))
save_images(generator, iteration + 1)losses = []、accuracies = []、iteration_checkpoints = []
#損失、精度、およびイテレーションごとのチェックポイントを格納するためのリストを初期化。
def train(iterations, batch_size, sample_interval):
#train 関数を定義。この関数は、訓練のメインループ
X_train = load_images("./resized_images_40")
#画像データを読み込む。load_images 関数は、指定されたディレクトリから画像を読み込む。(以降で定義)
X_train = X_train / 127.5 - 1.0
#画像のピクセル値を正規化。通常、画像のピクセル値は0から255の範囲だが、これを-1から1の範囲に変換。
real_label = np.ones((batch_size, 1))fake_label = np.zeros((batch_size, 1))
#本物の画像と偽物の画像のラベルを定義。
for iteration in range(iterations):
#指定されたイテレーション数だけ訓練を繰り返すidx_real = np.random.randint(0, X_train.shape[0] - 1, batch_size)idx_fake = np.random.randint(0, X_train.shape[0] - 1, batch_size)
#ランダムなインデックスを生成し、本物の画像と偽物の画像のバッチを選択。
#np.random.randint(a, b, size) 関数は、a 以上 b 未満の範囲からランダムに整数を size 個生成する。z = np.random.normal(0, 1, (batch_size, noise_dim))
#正規分布からランダムなノイズを生成。これはGeneratorの入力として使用。
gene_imgs = generator.predict(z)
#Generatorを使用して、ノイズから偽の画像を生成。
d_loss_real = discriminator.train_on_batch(batch_images_real, real_label)d_loss_fake = discriminator.train_on_batch(gene_imgs, fake_label)
#Discriminatorを訓練。本物の画像と偽物の画像をそれぞれ使用して損失を計算。
#train_on_batch メソッドは、バッチで訓練するために使用されます。このメソッドは、入力データと対応する正解ラベル(または目標値)を受け取り、モデルの重みを更新します。以下に、このメソッドの引数と使い方を説明します。
d_loss, accuracy = 0.5 * np.add(d_loss_real, d_loss_fake)
#Discriminatorの損失と精度を計算します。
g_loss = gan.train_on_batch(z, real_label)
#GANモデルを訓練。GANは、生成された画像を本物と誤認させるように学習します。
#real_labelは、生成器(Generator)の訓練時に使用される目標値。目標値として本物の画像に対応するラベルが与えられます。
(iteration + 1) % sample_interval == 0
#サンプル間隔ごとに、損失や精度を保存して結果を表示
save_images(generator, iteration + 1)
#生成された画像を保存
画像ロードの関数を定義する
今回は独自の画像データを使うので、モデルに画像を読み込ますためのロード関数が必要になります。ここでは、それを定義していきましょう!
def load_images(directory):
images = []
for filename in os.listdir(directory):
img = cv2.imread(os.path.join(directory, filename))
if img is not None: # 画像の読み込みが成功した場合のみ処理を続行
img = cv2.resize(img, (width, height))
images.append(img)
else:
print(f"Warning: Failed to load image {filename}")
if len(images) == 0:
print("Error: No images loaded")
return None
else:
return np.array(images)def load_images(directory):
#load_images 関数を定義。この関数は、指定されたディレクトリから画像を読み込むimages = []
#画像を格納するための空のリスト images for filename in os.listdir(directory):
#指定されたディレクトリ内のファイルを1つずつ反復処理する。img = cv2.imread(os.path.join(directory, filename))
#os.path.join を使用して、ディレクトリとファイル名を組み合わせてファイルのパスを作成
#cv2.imread を使用して画像を読み込む。if img is not None:
#画像が正常に読み込まれたかどうかをチェックimg = cv2.resize(img, (width, height))
#読み込まれた画像を指定された幅と高さにリサイズimages.append(img)
#リサイズされた画像を images リストに追加します。
else:
#画像が読み込まれなかった場合(img が None の場合)に実行されるブロック
print(f"Warning: Failed to load image {filename}")
#警告メッセージを出力し、どの画像が読み込めなかったかを表示
if len(images) == 0:
#読み込まれた画像がない場合をチェックします。
print("Error: No images loaded")
#エラーメッセージを出力します。
return None
#画像が読み込まれなかった場合は None を返すelse:
#それ以外の場合(画像が1つ以上読み込まれた場合)return np.array(images)
#images リストをNumPy配列に変換して返す。 NumPy配列は、後続の処理で使用できる形式にデータを整形する。
これでモデルに独自の画像データを読み込むことができます。
生成画像の保存
画像を保存して目視できるようにしましょう!
def save_images(generator, iteration, directory='face-gan_images', image_grid_rows=4, image_grid_columns=4):
if not os.path.exists(directory):
os.makedirs(directory)
z = np.random.normal(0, 1, (image_grid_rows * image_grid_columns, noise_dim))
gene_imgs = generator.predict(z)
gene_imgs = 0.5 * gene_imgs + 0.5
fig, axs = plt.subplots(image_grid_rows, image_grid_columns, figsize=(4, 4), sharey=True, sharex=True)
cnt = 0
for row in range(image_grid_rows):
for col in range(image_grid_columns):
axs[row, col].imshow(gene_imgs[cnt])
#カラーなので前回までのgene_imgs[cnt, :, :, 0], cmap='gray'は不要
axs[row, col].axis('off')
cnt += 1
fig.savefig(f"{directory}/iteration_{iteration}.png")
plt.close(fig)引数のdirectory=を変えないと、以前の保存画像に上書きされてしまうので、これは変えておきましょう!
モデルの実行&保存
バッチサイズを変えると、学習に影響が出ます。それ以外のパラメーターはお好みでどうぞ!
iterations = 20000
batch_size = 128
sample_interval = 100
train(iterations, batch_size, sample_interval)
generator.save('40x40color-Face-gene.keras')
discriminator.save('40x40color-Face-dis.keras')
gan.save('40x40color-Face-gan.keras')これもよく登場するので割愛します。
ファイルの実行
では、実行していきましょう。実行方法は人それぞれですが、私の場合はCMDでファイル名を入力することで実行しています。
ファイル名.pyこれで、いい感じの出力がされたら完了です!
学習モデルで1枚ずつ確認してみよう!
今までは、4×4で画像を確認しましたが、サイズを大きく確認したいので1枚で出力されるようにしましょう。
import numpy as np
import matplotlib.pyplot as plt
from keras.models import load_model
import os
import cv2
noise_dim=100
# 保存したGANモデルの読み込み
generator = load_model('40x40color-Face-gene.keras')
def generate_images(generator, save_directory, num_images=10):
if not os.path.exists(save_directory):
os.makedirs(save_directory)
noise = np.random.normal(0, 1, (num_images, noise_dim))
generated_images = generator.predict(noise)
for i in range(num_images):
img = (generated_images[i] + 1) / 2 # 画像のスケーリングを元に戻す
plt.imshow(img)
plt.axis('off')
plt.savefig(f"{save_directory}/generated_image_{i+1}.png")
plt.close()
# 画像を保存するディレクトリと生成する画像の枚数を指定して実行
generate_images(generator, "generated_images", num_images=40)generator = load_model(’40x40color-Face-gene.keras’)
#括弧内には各自の学習済み生成器ファイル名を入れてください。
generate_images(generator, “generated_images”, num_images=40)
#手動generated_imagesを作って、それを保存先ディレクトリに指定します。
#num_images=40は保存する画像数です。
これで、大きなサイズで画像を確認できるようになりました。
おわりに
今回はカラー画像の生成方法を紹介しました。もっと、質を高めたい方は、層を複雑にしたりパラメーターの値をカスタマイズしてみてください。
では、次回はグレースケール画像で、サイズの大きな画像を生成できるようにします。流れは、今までやってきたことと同じなので、ササっとやっていきましょう!